
SLAE64 - Assignment 3 - EggHunter
The third assigment for the SLAE64 certification asks to study about the EggHunter shellcode and to create a working demo of it.
Egg Hunting (tl;dr)
The most basic Buffer Overflow exploit technique consists of creating a string that contains garbage bytes, a memory address to be overwritten on the return address (which will be popped into EIP during the ret procedure) and some shellcode to be then executed, being invoked via a JMP ESP.
This is a conceptual representation of the payload, where section ‘A’ contains garbage bytes, section ‘B’ the memory address of a suitable instruction to redirect the execution flow to the section ‘C’:

It is all working in the concept, but what happens if the ‘C’ section is too small to contain the intended shellcode? What if we could place our complete shellcode in other memory sections and then search for it and execute it?
This is the exact purpose of the EggHunting technique:
- to put the complete shellcode somewhere in the process memory area (even in the ‘A’ section) prefixing it with an ‘egg’ - simply, a marker - repeated two-times (to ensure uniqueness)
- to create a very short shellcode - the Egg Hunter itself - to find the double-egg in memory and then redirect the execution flow just right after it.

EggHunter shellcode
Skape’s paper “Safely Searching Process Virtual Address Space” can be easily defined as both the blueprint and the masterpiece of Egg Hunting. This document presents three different implementations of EggHunter shellcode for Linux and three implementations for Windows.
The EggHunting shellcode leverages the access() syscall. For each memory page, the shellcode tries accessing the address; if 0xF2 error is returned (EFAULT) it means that the pointer is outside the accessible address space, and therefore it goes to the next page; if page is accessible, addresses are scanned in order to find the egg (0xDEADBEEF in the shellcode) repeated twice. When it is found, the address of the start of the shellcode is contained into register RDI and therefore a jump to RDI is performed.
In order to test the correct execution, I have added a “jmp_to_egg” label just right before the jump to the shellcode found after the egg, and an appropriate breakpoint has been added:
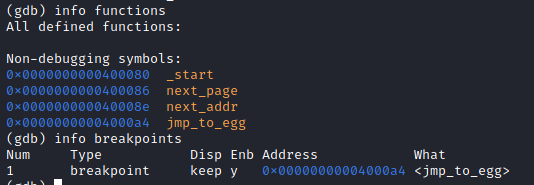
When the breakpoint is reached, it means that the egg has been found - repeated two times - in memory.

As expected, the next instruction will be a jmp rdi:

Looking at the value in the register RDI, we see that in the execution it is 0x4000b0. Given that the shellcode (label ‘Shellcode’) starts at 0x4000a8 and the first 8 bytes are the two copies of the egg, it means that 0x4000b0 is the start address of the actual shellcode right after the eggs.

Running the compiled (remember that Stack has to be marked as executable, therefore I used the ‘compileExec.sh’ utility) program in the terminal it behaves as expected, i.e. exits with status code 13:

I created another version of the same program, under /Test2/ directory: it is exactly the same except for the shellcode, which is at the top of the ‘.text’ section instead of the ‘.data’ section. It behaves in the same exact way:

This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification: http://www.securitytube-training.com/online-courses/x8664-assembly-and-shellcoding-on-linux/index.html.
Student ID: PA-29059
GitHub repository: https://github.com/andrea-perfetti/SLAE64-Exam
This assignment has been written on a Kali Linux 2021.1 64-bit virtual machine:
┌──(kali㉿kali)-[~]
└─$ uname -a
Linux kali 5.10.0-kali3-amd64 #1 SMP Debian 5.10.13-1kali1 (2021-02-08) x86_64 GNU/Linux